内容概要
《守望先锋》使用了 ECS 的架构方式,但是为什么 ECS 会成为一个更好的架构呢?这篇文章就来讲一下 ECS 背后的‘面向数据的设计(Data-Oriented Design)’,你将会明白这个 Why。进而,你将发现面向数据的设计是多么的重要!
【欢迎转载,请注明作者:景夫,原文出处:做游戏的景夫】
来自”玻璃渣”的 Timothy Ford 在 GDC 2017 大会做了一个专题演讲“《守望先锋》架构设计与网络同步(Overwatch Gameplay Architecture and Netcode)”,其中介绍的 ECS 架构一时引起众多关注。国内也掀起了一阵子 ECS 热潮,很多人普遍的认为 ECS 是一种更好的组织复杂网络游戏逻辑的架构,说是可以使得系统之间更好的解耦等等,窃深不以为然。这是因为很多同学没有研究 ECS 这种设计的来龙去脉,以及它的更深一个层面上的思考。例如 Entity 为什么只能是一个 ID ? Component 为什么只能包含数据?
而在转过年来的 Unity 2018 新版中也支持了 ECS 架构,并且性能有大幅提升!这才是重点,这才是理解 ECS 的一个核心角度。

ECS - Entity, Component, System 这一系列概念都是说起来非常简单清晰的,那么为什么 ECS 会成为游戏行业的主流设计思想呢?这还要从”面向数据的设计(Data-Oriented Design)”讲起。ECS 是一种面向数据的设计在咱们游戏、引擎行业中的成功应用,要想理解“WHY”,就必须要理解面向数据的设计这一思想!
面向数据的设计
现代的程序设计思想要求我们以计算机的方式去解决问题(而不是以人脑的方式),“面向数据的设计”思想可以说是沿着这个方向又前进了一大步。这种程序设计的思想的出现和流行和计算机硬件的发展是息息相关的。乔布斯曾经引用过 Alan Kay 的一句名言说软件开发者必须关心硬件。下面我就结合计算机硬件的发展现状来说明一下这种设计思路的优势在哪里,也就是说为什么 ECS 之类是更好的设计!
内存与 CPU 的性能差距
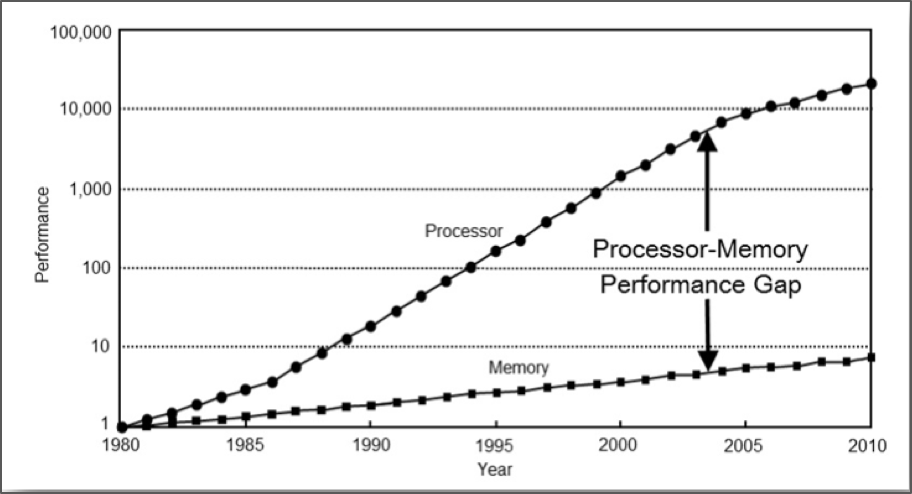
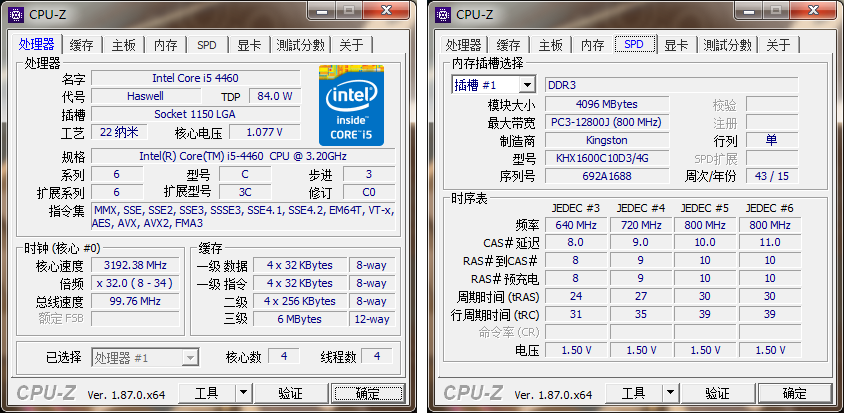
在过去几十年 CPU 的工作频率得到了快速提升,而内存(DRAM)的工作频率提升却没有那么快!我作为一个电脑 DIY 玩家是有切身体会的,选购主板、内存、CPU的时候,有两个常见的概念:外频和倍频!外频也就是系统总线工作的频率。例如我家里这台电脑的总线速率是1GHz,CPU 的主频是3.2GHz,倍频为32,而内存主频只有800MHz。CPU通过倍频机制工作在更高的主频之上。从下面这张图,我们可以非常直观的看出内存与 CPU 之间的性能差距。
对于 CPU 来说“内存”已经是一个非常缓慢的设备了!为了少被内存拖后腿,CPU 内部集成了越来越多的 Cache。CPU 的内存预读取(prefetch)、多级 Cache 对于我们软件开发者都是透明的,为了验证这个点上的性能差异,我写了一个小小的测试程序。这个测试程序分别以“基于组件的对象设计”和“基于数据的设计”两种方式,对 50000 个 GameObject (或者叫做 Entity) 的 Transform 矩阵进行计算。核心的计算代码都是一样的,最重要的差别就是这些 Transform 数据的内存布局不同。测试的结果十分惊人,在我的电脑上前者要比后者慢 2.8 倍! 这个测试程序的代码请见文章后面的附录。
测试的两者矩阵计算都是一样一样的,它们的差别主要就是内存组织方式,请见下图:
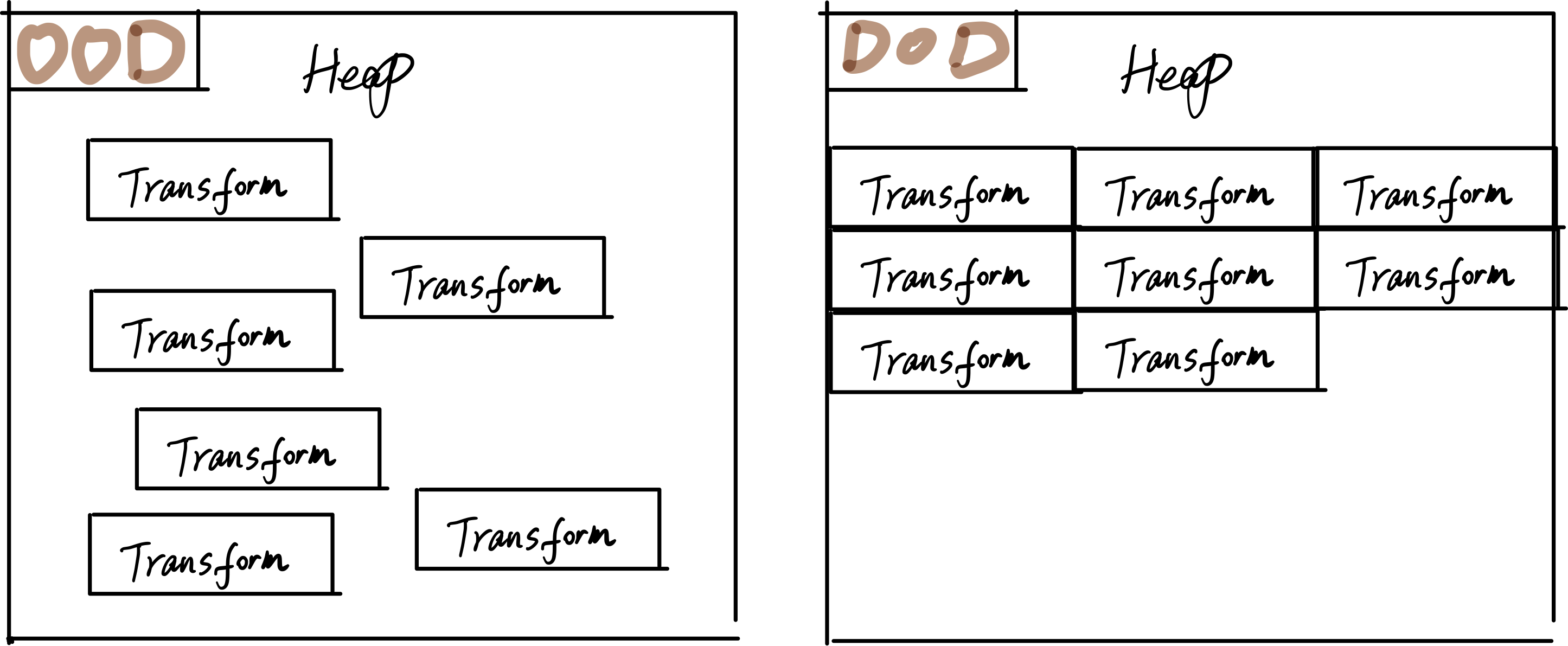
由于内存与 CPU 之间的性能差距还在加大,所以将数据以 Cache 友好的方式组织,可以显著提升程序性能。 而且,迄今为止,在这个点上,编译器是帮不上忙的!
多核与并行计算
2005年 Herb Sutter 发表了著名的文章:The Free Lunch Is Over,宣称“免费的午餐结束了”,并行计算是软件开发的下一次变革。所谓“免费的午餐”是指 CPU 主频快速提升的那些年,软件开发者不用花费什么力气就可以得到更高的性能。在 2005 年 CPU 的主频提升已经受到了硅晶片的物理限制,CPU 厂商改走“多核”路线了,作为软件开发者必须掌握“并行计算”的编程技巧才能得到更高的性能。一时间并行编程成了热门,回头看看,OpenMP、Threading Building Blocks 好像都火了一阵子,但最终。。。。至少在3D引擎、游戏开发领域少有人问津。
面向对象在并行编程方面有天生的劣势! 我们通过“封装”把数据放到对象内部去管理,一个对象往往管理了其抽象概念之下的复杂数据。在这种设计之下,这些数据之间的“并行计算”的关系是很难理清的,因为很多东西被刻意“隐藏”起来。我曾经花了很多时间在虚幻引擎的源代码上,虚幻3、4引擎就是一个典型的以面向对象为核心设计思想的多线程架构。现在虚幻4包括主线程、渲染线程、RHI线程、Texture Streamming线程,IO线程、物理线程等等!就拿渲染线程和主线程的交互方式来看,首先你就会发现大量的冗余数据,游戏逻辑层的对象中渲染相关的数据,必须通过 Primitive Proxy 的方式拷贝一份,发送到渲染线程;其次,还是有很多对象是在两个线程上同时要操作的,例如 View 系列的类,想改底层的话,分分钟被锁死!
面向数据的设计,从起点就考虑并行的问题! 在面向数据的设计中,设计的焦点是数据,首先要把数据理清楚,然后把逻辑分离出去。这样做的最大的好处是,每个逻辑模块对数据的读或是写是可以清晰界定的!这样一看,那些计算可以并行,那些是互相依赖的,就一清二楚了!这方面 Unity3D 的 JobSystem 是很成功的!每一个 Job class 可以通过指定 UpdateAfter/Before Attribute 的方式建立依赖关系图,而引擎根据这个图自动调度任务的并行执行!实际上,我认为UpdateAfter/Before 这个名字起的不好,因为本质上你不是在排序 Job 的执行顺序,而是要思考对 ComponentData 的读写!
总结
下面我们就通过对比来回顾一下“面向数据的设计”的核心思想:
| 面向对象(OOD) | 面向数据(DOD) |
|---|---|
| 设计的焦点是“对象” | 设计的焦点是“数据” |
| 将数据和行为封装在一起 | 数据和逻辑分离 |
| 将数据隐藏到对象内部 | 将数据开放给逻辑 |
| 以人更容易理解的方式组织对象 | 以计算机更友好的方式组织数据 |
通过理解“面向数据的设计”,我们就可以对 ECS 架构有一个更清晰的认识:不仅知道“是什么”,还知道了“为什么”。
- 与“基于组件的对象设计”不同,ECS 架构中的 Component 只包含数据。例如使用 C++ 编程的话,Component就可以是 POD 类型(Plain Old Data)。Entity 也不是面向对象那样把组件、行为封装起来,而是只对应一个 ID。整个这个机制的设计使得所有组件可以在 World 中统一管理的时候,可以使用连续的内存布局,大大提高 CPU 的 Cache 命中率。
- System 对于组件数据的“读写”是可以明确定义的。从这个数据的读写就可以分析出系统之间的依赖关系,形成一个 DAG。基于这种分析也就可以确定那些系统是可以并行执行的!典型的就是 Unity3D 的 JobSystem。
ECS 只是“面向数据的设计”思想下的一种设计模式,可以预见接下来在各个特定的领域会产生更多的以数据为中心的设计模式,特别是在并行计算领域,面向数据的设计将占主导地位!
【题外话】
DRAM 必须以一定频率充电才能保持其存储的内容不丢失。Oculus 现任的首席科学家迈克尔·亚伯拉什(Michael Abrash)在早年就写个一篇文章,讲图形程序优化的。其中讲到一个技巧就是计算每个汇编指令的时钟周期,然后手动排列汇编指令,避开这个 DRAM “充电”时间。因为在 DRAM 充电的时候是无法进行读写操作的!优化到如此程度,实在令人咋舌!
参考资料
- Stoyan Nikolov, “OOP Is Dead, Long Live Data-oriented Design”, 2018
- Tony Albrecht, “Pitfalls of Object Oriented Programming”, 2017
- Mike Acton, “Data-Oriented Design and C++”, 2014
附录:测试代码
- DOD.h
#pragma once
#include <vector>
#include <glm/glm.hpp>
#include <glm/ext.hpp>
#include <glm/gtc/matrix_transform.hpp>
using namespace glm;
using namespace std;
namespace DOD {
struct Transform {
vec3 mPosition;
quat mRotation;
vec3 mScale;
mat4 mLocalToWorld;
};
class System {
public:
virtual void tick(float deltaTime, void* components, int count) = 0;
};
class SceneGraph : public System {
public:
virtual void tick(float deltaTime, void* components, int count) override {
Transform* transformData = static_cast<Transform*>(components);
for (int i = 0; i < count; i++) {
Transform& trans = transformData[i];
trans.mLocalToWorld = mat4(1);
trans.mLocalToWorld =
glm::translate(trans.mLocalToWorld, trans.mPosition);
trans.mLocalToWorld *= glm::mat4_cast(trans.mRotation);
trans.mLocalToWorld = glm::scale(trans.mLocalToWorld, trans.mScale);
}
}
};
class World {
public:
World(int entityCount) { mTransformData.resize(entityCount); }
void tick(float deltaTime) {
mSceneGraph.tick(deltaTime, &(mTransformData[0]),
(int)mTransformData.size());
}
private:
SceneGraph mSceneGraph;
vector<Transform> mTransformData;
};
} // namespace DOD
- OOD.h
#pragma once
#include <list>
#include <memory>
#include <string>
#include <glm/glm.hpp>
#include <glm/ext.hpp>
#include <glm/gtc/matrix_transform.hpp>
using namespace std;
using namespace glm;
namespace OOD {
class GameObject;
class Component {
public:
typedef shared_ptr<Component> Ptr;
Component(GameObject* obj) : mObject(obj) {}
virtual void tick(float deltaTime) = 0;
private:
GameObject* mObject;
};
class Transform : public Component {
public:
typedef shared_ptr<Transform> Ptr;
Transform(GameObject* obj) : Component(obj), mScale(1), mLocalToWorld(1) {}
virtual void tick(float deltaTime) override {
mLocalToWorld = mat4(1);
mLocalToWorld = glm::translate(mLocalToWorld, mPosition);
mLocalToWorld *= glm::mat4_cast(mRotation);
mLocalToWorld = glm::scale(mLocalToWorld, mScale);
}
private:
vec3 mPosition;
quat mRotation;
vec3 mScale;
mat4 mLocalToWorld;
};
class GameObject {
public:
typedef shared_ptr<GameObject> Ptr;
GameObject() {}
template <typename T>
shared_ptr<T> addComponent() {
shared_ptr<T> component(new T(this));
mComponents.push_back(component);
return component;
}
void tick(float deltaTime)
{
for (auto iter = mComponents.begin(); iter != mComponents.end(); ++iter) {
(*iter)->tick(deltaTime);
}
}
private:
list<Component::Ptr> mComponents;
const GameObject& operator=(const GameObject& other) = delete;
GameObject(const GameObject& other) = delete;
};
} // namespace OOD
- main.cpp
```cpp
#include
#include
using namespace std; using Clock = chrono::steady_clock;
#include “DOD.h” #include “OOD.h”
int main() { const int ENTITY_COUNT = 50000; const int TEST_COUNT = 16;
float sum = 0; Clock::duration timeOOD, timeDOD;
for (int i = 0; i < TEST_COUNT; i++) { // OOD Test { list<OOD::GameObject::Ptr> gameObjects; for (int i = 0; i < ENTITY_COUNT; i++) { OOD::GameObject::Ptr go(new OOD::GameObject()); go->addComponent<OOD::Transform>(); gameObjects.push_back(go); }
Clock::time_point start = Clock::now();
for (auto iter = gameObjects.begin(); iter != gameObjects.end(); ++iter) {
(*iter)->tick(0.1f);
}
timeOOD = Clock::now() - start;
}
// DOD Test
{
DOD::World world(ENTITY_COUNT);
Clock::time_point start = Clock::now();
world.tick(0.1f);
timeDOD = Clock::now() - start;
}
float t1 = chrono::duration_cast<chrono::duration<float> >(timeOOD).count();
float t2 = chrono::duration_cast<chrono::duration<float> >(timeDOD).count();
float r = t1 / t2;
sum += r;
cout << "OOD Time = " << timeOOD.count()
<< ", DOD time = " << timeDOD.count() << ", OOD/DOD = " << r << endl; }
cout « “Average = “ « sum / TEST_COUNT « endl « “Press Enter…”;
getchar();
} ```
Written on November 17th, 2018 by 景夫