内容概要
渲染3D图形需要模型,这篇文章我们就聊一下处理模型的方式,以及glTF中如何定义Mesh数据的。
【欢迎转载,请注明作者:景夫,原文出处:做游戏的景夫】
在上一篇文章中我们介绍了场景中对象之间的层次关系,接下来我们就探讨单个物体在三维空间中的表示。
要渲染三维空间中的物体,首先就要在三维空间中表示物体的造型。目前图形学中最常用的方法叫做“边界表示法( Boundary Representation )”,即用一组多边形或者曲面来定义物体的边界,它们可以区分了空间中哪些部分是物体的内部,哪些是物体的外部。其中使用多边形的方式更通用一些,构造一个物体边界的一组多边形就被称为“ Mesh ”。 在这里我们先讨论静态 mesh,也就是自身不发生形变的 mesh ,glTF 也支持蒙皮和骨骼动画,我们后面再讲。
也许现在三角形太流行了,大家可能不习惯了使用多边形。实际上,现在建模软件还在大量使用多边形,最后这些模型导入 3D 引擎的时候会再进行三角形化( triangularization )。三角形的流行是在 GPU 兴起之后的事儿,因为三角形更有利于硬件去实现和优化。在早期的 3D 游戏中,例如 Quake 使用软件渲染,它使用凸多边形。在 OpenGL 早期的 API 版本中也有对多边形的支持: glBegin() 支持 GL_POLYGON 模式,而在3.0以后版本的 OpenGL API 中已经不再支持了,下面我们讨论的 Mesh 也就使用三角形模式了。
Mesh 的数据组织
OpenGL 或者其他图形 API 都普遍支持下面这三种三角形 Mesh 的拓扑结构:
- Triangle List:每三个顶点组成一个三角形
- Triangle Strip:每增加一个顶点,和前面的两个顶点组成一个三角形(共享前面两个顶点)
- Triangle Fan:每增加两个顶点,与第0个顶点组成一个三角形(共享第0个顶点)
OpenGL 支持两种向 GPU 提交 Mesh 数据的方式:
-
DrawArrays 方式
把 Mesh 中的三角形的所有顶点数据,按照上面那三种方式之一排列形成一个顶点数组,就可以让 GPU 去绘制所有这些三角形了。 -
DrawElements 方式
在一个 Mesh 中很多三角形是互相连接在一起的,具体的说,两个三角形会共用一条边,那么这条边上的两个顶点则可以共享。为了共享顶点,就需要引入“顶点索引”。(做实时渲染的人最抠门了,各种省 )。把所有的顶点放在一个数组中,然后另外使用一个 index buffer 通过数组下标来引用顶点数组中的顶点数据。把 Mesh 所需的三角形,使用 index buffer 按照前面说的三种拓扑结构列举出来,就可以提交到 GPU 去绘制了。
)。把所有的顶点放在一个数组中,然后另外使用一个 index buffer 通过数组下标来引用顶点数组中的顶点数据。把 Mesh 所需的三角形,使用 index buffer 按照前面说的三种拓扑结构列举出来,就可以提交到 GPU 去绘制了。
通过 index buffer 可以有效的减少 Mesh 的内存占用,并且能够提升 GPU 的绘制效率,详见Vertex Cache 优化小节,对于复杂的模型来说,这是一种应该优先使用的方式。
顶点缓冲的两种内存布局
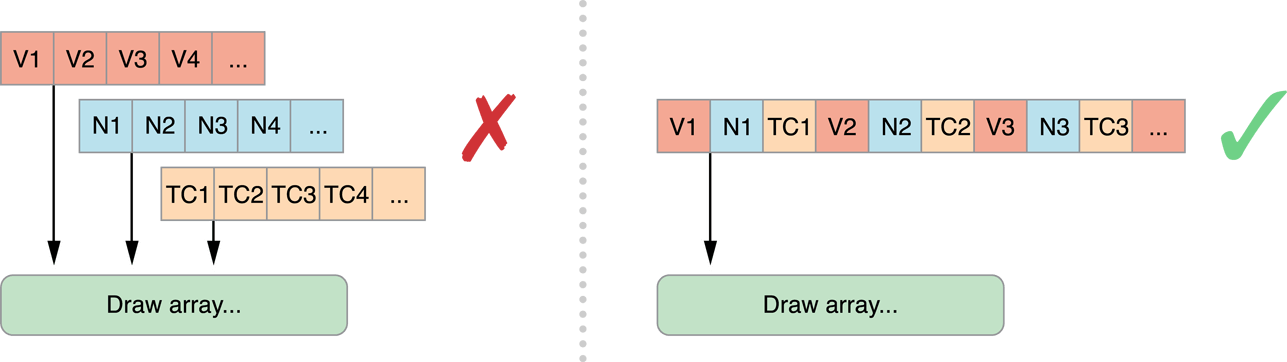
上图来自苹果开发者网站
一个顶点可能有多项数据,在 OpenGL API 中称之为 Attribute ,这些数据的排列有两方式,如上图所示。这两种方式都可以被 OpenGL 系列 API 所支持,但它们的效率上却有所差别:
- struct of arrays
如上图左侧所示的数据结构,我们把顶点位置、法线等各自定义一个结构体(一般也就是 vec2、vec3、vec4 啦)的数组提交给 GPU。 - array of structs
假想我们把每个顶点都定义一个结构体:struct MyVertex { vec3 pos; vec4 normal; vec2 uv; }把这个结构体数组提交给 GPU。
第二种方式的 Vertex Buffer 在内存布局上是连续的,GPU 访问起来更高效。 应该尽量使用第二种方式,除非你需要单独计算更新某个顶点属性,而其他顶点属性保持不变。另外,Vertex Buffer 保持4字节对齐,也有助于提高 GPU 的内存访问效率。
Vertex Cache 优化
GPU 在渲染每个三角形时,三角形的每个顶点都要进行计算,也就是我们通过 Vertex Shader 进行的处理。当我们使用 DrawElements 的方式绘制 Mesh 时,GPU 会利用内部的一个很小的 Cache (一般是12到24个顶点,根据硬件实现会不同) 来保存顶点处理结果,通过 index 来判断是否命中 Cache,从而避免顶点的重复计算,提升效率。如果使用 DrawArrays 的话, Vertex Cache 是无法起作用的。
通过对 Mesh 进行预处理,可以更好的利用 Vertex Cache 。GPU 一般使用 LRU(least recently used)策略处理 cache 替换,所以这个预处理的优化,主要就是将 Mesh 中的三角形进行排序,使得每个进入渲染管线的顶点 Index 尽量接近前面的。
顶点的法线
有一个小问题你有没有想过:顶点是一个点,它哪里来的什么法线?法线是垂直于一个平面的单位向量啊!一个点怎么会有法线?
我想所谓的“顶点的法线”是因为渲染计算需要,才被我们“捏造”出来的一项数据,其主要目的是希望 Shading 产生出尽量平滑的视觉效果。从这个角度说,某些情况下顶点法线也是有道理的,例如,当我们用一组三角形去近似一个曲面的时候,某个顶点的法线就应该是曲面上这一点的法线;而对于一般性的三角形集合来说,可以想象成共享这个顶点的所有三角形的“面法线”的某种平均。
一般情况下,顶点的法线应该由建模工具提供。在建模工具中提供了一些工具(例如光滑组等),帮助艺术家们调整法线的计算方式,产生他们想要的结果。有些时候,在模型导入3D引擎的时候也可以重新计算法线。
glTF 中的 Mesh 数据组织
"meshes": [
{
"primitives": [
{
"attributes": {
"NORMAL": 1,
"POSITION": 2
},
"indices": 0,
"mode": 4,
"material": 0
}
],
"name": "Mesh"
}
]
上面这一段 JSON,就是 glTF 文件中一个典型的 meshes 字段,它是一个数组。数组的每个成员是一个 mesh 对象,每个 mesh 对象有两个字段:name 和 primitives。primitives 又是一个数组,数组的每个成员是一个 primitive 对象,这里的 primitive 在有的引擎中也叫做 sub mesh 或者 mesh section。
primitive 是实际存储几何体数据的地方:
-
attributes
来指定顶点数据,前面我们提到过 GL 中顶点的数据项叫做 attribute;
其中每个 attribute 的值都是一个数字,例如:”NORMAL”: 1,那么这个值“1”的含义是什么呢?它是用来索引二进制数据结构的,具体来讲是索引“accessor”。glTF 是一个面向实时渲染的内容格式标准,它使用一个二进制文件来保存 mesh 的顶点、Index 这些数据,大致结构如下图中橙色的部分。glTF 中的二进制数据处理方式,具体的我们在下一文中再讲。
-
indices
用来指定三角形的顶点索引数据,这个项目可以没有,则表示这是一个 non-indexed mesh;其值同样也是引用 accessor 的; -
mode
用来指定绘制的方式,其值是 OpenGL 中定义的常量,具体包括:- 0 POINTS
- 1 LINES
- 2 LINE_LOOP
- 3 LINE_STRIP
- 4 TRIANGLES
- 5 TRIANGLE_STRIP
- 6 TRIANGLE_FAN
- material 用来指定这个 primitive 所使用的材质;它的值是一个数字,用来索引 glTF 中的 “materials” 数组。具体的,在后续讲到材质的时候,我们再详细讲。
具体如下图中的蓝色部分所示。

在场景节点中引用 Mesh
"nodes" : [
{
"mesh" : 0,
"translation" : [ 1.0, 0.0, 0.0 ]
}
]
在前面一节讲 glTF 的 Scene Graph 数据的时候,我们讲到 glTF 的 JSON 数据中有一个 “nodes” 数组用来保存整个 Scene Graph,数组中的每个元素是 Scene Graph 中的一个节点。场景节点可以有一个 “mesh” 字段,其值是一个数字,用来索引 “meshes” 数组中的 mesh 对象。根据这个字段,渲染程序就可以找到相应的 mesh ,并为这个节点添加 mesh 渲染组件。节点中的这个 mesh 字段,基本上对应 Unity 的 MeshFilter + MeshRenderer 两个组件的功能( MeshFilter 指定渲染哪个 mesh 对象,MeshRenderer实现渲染功能 )。
参考资料
- OpenGL ES 2.0 Reference Pages, Khronos Group
- Best Practices for Working with Vertex Data, Apple Developer
- Linear-Speed Vertex Cache Optimisation, Tom Forsyth, RAD Game Tools
- NvTriStrip Library, NVIDIA